In the past, when I read technical books, I tend to skim through them, looking for keywords and only read the part that is relevant at the moment, and move on. Sometimes I would make an attempt at finishing a whole book, but a few months or even years later, I haven’t even finished the first 3 chapters!
I took a different approach recently. Now I’ve set up daily goals to read 50 or more pages or a key section of a technical book, and follow through. I am reading two technical books at the moment: Itzik Ben-Gan et al’s Inside Microsoft SQL Server 2005: T-SQL Querying, and Baron Schwartz et al’s High Performance MySQL. It’s nice to read database books that focus on different vendor implementations (SQL Server, MySQL, Oracle, etc.), because each one explains certain things from a slightly different angle, with slightly different language, and at times this gives you a better feel of the overall picture and clarity to certain key concepts.
Here I am talking about quality technical books, though, because the industry churns out way too much junk. It certainly is a waste of time and money on poorly thought out and written books.
Anyway, today I went through Itzik Ben-Gan’s performance tuning chapter. I used SQL Server 2008’s Management Studio to do tests against a SQL Server 2005 instance. I noticed an interesting change in terminologies: in SQL Server 2008, a bookmark lookup on a table with clustered index is now called Key Lookup, on a table without clustered index is (still) called RID lookup. Here are some screen shots:
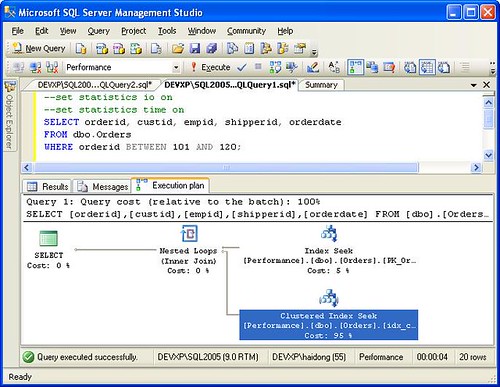
Bookmark lookup in SQL Server 2005 on a table with cluster index
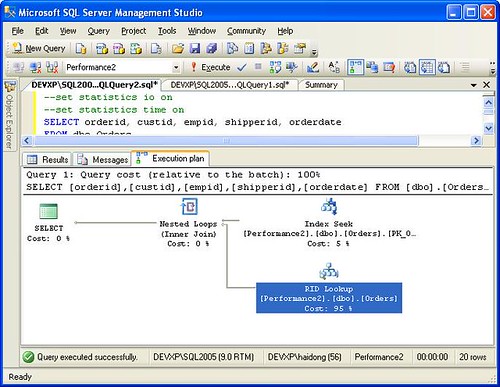
Bookmark lookup in SQL Server 2005 on a table without cluster index
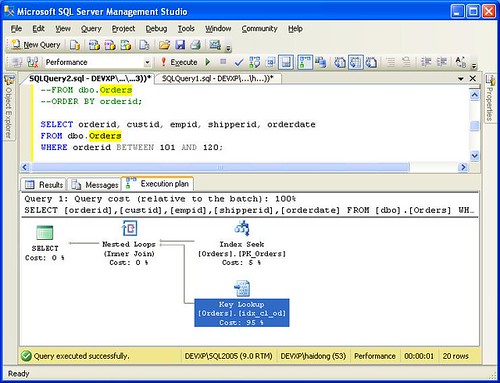
Bookmark lookup in SQL Server 2008 on a table with cluster index
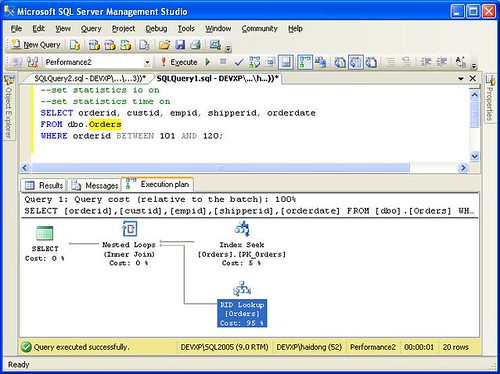
Bookmark lookup in SQL Server 2008 on a table without cluster index
To recap, here are the terms used for bookmark lookups in the 3 most recent SQL Server releases:
SQL Server 2000: bookmark lookup
SQL Server 2005: RID lookup on a heap, Clustered Index Seek on a table with clustered index
SQL Server 2008: RID lookup on a heap, Key Lookup on a table with clustered index
SQL Server’s clustered index implementation went through some interesting changes. Prior to SQL Server 7, all non-clustered index contains a pointer to the actual row(s) that has the value of the indexed keys. This pointer (RID, Row ID) physically points to the position on which page in which internal file that row is at. Starting from SQL Server 7, for tables without a clustered index (heap), the implementation stays the same. However, for tables with clustered index, the pointer is the clustered index.
This can potentially have a big impact for bookmark lookup on tables with clustered index. Here is why: to do lookups, SQL Server needs to traverse through clustered index, thus more reads. The number of additional reads this causes depends on the level of clustered index and how many rows the query touches. Suppose the clustered index has 3 levels (root, leaf, and one intermediate level), then a single bookmark lookup will incur 3 additional logical reads. If the query touches 2000 rows, then bookmark lookup will cause 6000 additional reads.
Note I am not bashing against clustered index though. Overall, in my opinion, the benefits of clustered index definitely outweighs its drawbacks. Now this post is getting long and I want to go back to my books, so I will stop here.
One response to “Different lingoes for bookmark lookup and why bookmark lookup can be costly”
[…] This post was Twitted by sql_joker […]